Frame Preemption¶
Goals¶
In conventional Ethernet networks, when a high-priority frame arrives at a network interface while a lower-priority frame is already being transmitted, the high-priority frame must wait until the entire lower-priority frame transmission is completed before it can be sent. This head-of-line blocking can cause significant delays for time-critical frames, especially when large lower-priority frames are being transmitted. The delay is particularly problematic in Time-Sensitive Networking (TSN) applications where high-priority frames contain time-critical data that must be delivered with minimal and predictable latency.

Ethernet frame preemption, specified in the 802.1Qbu standard, addresses this problem by allowing higher priority frames to interrupt the transmission of lower-priority frames at the Media Access Control (MAC) layer. When a high-priority frame becomes available during the transmission of a lower-priority frame, the MAC can stop the lower-priority transmission, send the high-priority frame, and then resume the lower-priority frame transmission from where it left off. This mechanism ensures that high-priority frames experience minimal queueing delay, providing the low and predictable latency required for time-critical applications.

In this showcase, we will demonstrate Ethernet frame preemption and examine the latency reduction that it can provide. By the end of this showcase, you will understand how frame preemption works and how it can be used to improve the performance of time-critical applications in an Ethernet network.
4.6The Model¶
Overview¶
In time-sensitive networking applications, Ethernet preemption can significantly reduce latency. When a high-priority frame becomes available for transmission during the transmission of a low-priority frame, the Ethernet MAC can interrupt the transmission of the low-priority frame and start sending the high-priority frame immediately. When the high-priority frame finishes, the MAC can continue the transmission of the low-priority frame from where it left off, eventually sending the low-priority frame in two (or more) fragments.
Preemption is a feature of INET’s composable Ethernet model. It uses INET’s packet streaming API, so that packet transmission is represented as an interruptible stream. Preemption requires the LayeredEthernetInterface, which contains a MAC and a PHY layer, displayed below:
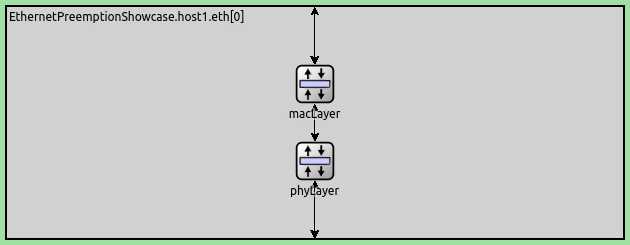
To enable preemption, the default submodules EthernetMacLayer and EthernetPhyLayer need to be replaced with EthernetPreemptingMacLayer and EthernetPreemptingPhyLayer.
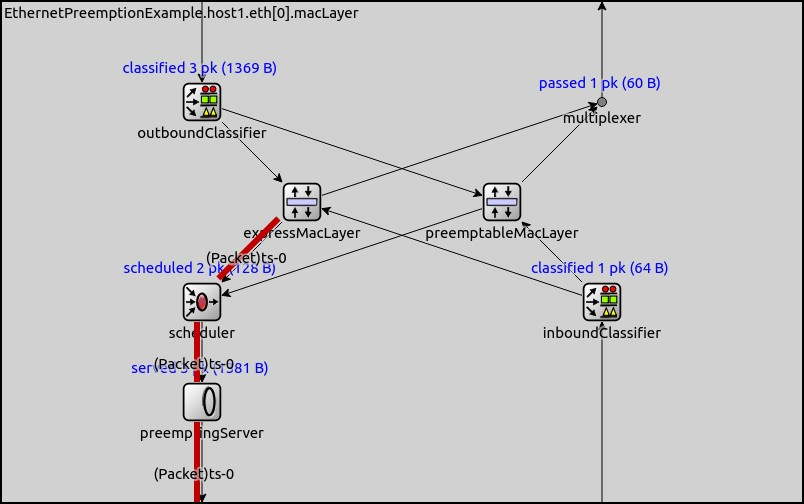
The EthernetPreemptingMacLayer contains two submodules which themselves represent Ethernet MAC layers, a preemptable (EthernetFragmentingMacLayer) and an express MAC layer (EthernetStreamingMacLayer), each with its own queue for frames:
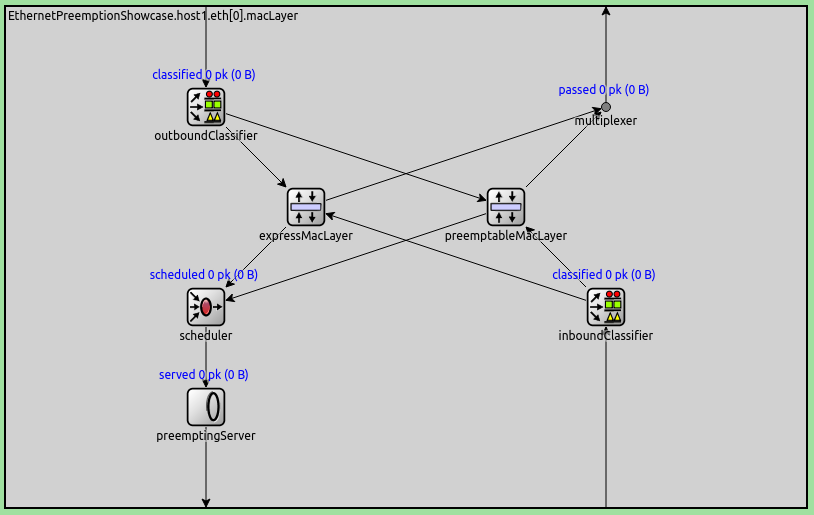
The EthernetPreemptingMacLayer uses intra-node packet streaming. Discrete packets enter the MAC module from the higher layers but leave the sub-MAC-layers (express and preemptable) as packet streams. Packets exit the MAC layer as a stream and are represented as such through the PHY layer and the link.
In the case of preemption, packets initially stream from the preemptable sub-MAC-layer.
The scheduler notifies the preemptingServer when a packet arrives at the express MAC.
The preemptingServer stops the preemptable stream, sends the express stream in full,
and then eventually it resumes the preemptable stream.
Interframe gaps are inserted by the PHY layer.
The EthernetPreemptingPhyLayer supports both packet streaming and fragmenting (sending packets in multiple fragments).
Configuration¶
The simulation uses the following network:
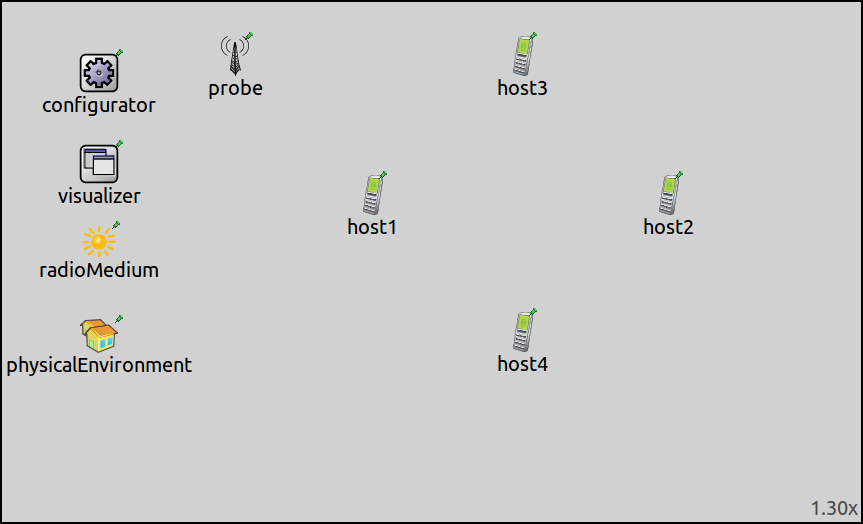
It contains two StandardHost’s connected with 100Mbps Ethernet and also a PcapRecorder
to record PCAP traces; host1 periodically generates packets for host2.
Primarily, we want to compare the end-to-end delay, so we run simulations with the same packet length for the low and high-priority traffic in the following three configurations in omnetpp.ini:
FifoQueueing: The baseline configuration; doesn’t use a priority queue or preemption.PriorityQueueing: Uses a priority queue in the Ethernet MAC to lower the delay of high-priority frames.FramePreemption: Uses preemption for high-priority frames for a very low delay with a guaranteed upper bound.
Additionally, we demonstrate the use of a priority queue and preemption with more realistic traffic:
longer and more frequent low-priority frames and shorter, less frequent high-priority frames.
These simulations are the extension of the three configurations mentioned above, and are defined
in the ini file as the configurations with the Realistic prefix.
In the General configuration, the hosts are configured to use the layered Ethernet model
instead of the default:
*.*.ethernet.typename = "EthernetLayer"
*.host*.eth[0].typename = "LayeredEthernetInterface"
We also want to record a PCAP trace, so we can examine the traffic in Wireshark. We enable PCAP recording and set the PCAP recorder to dump Ethernet PHY frames because preemption is visible in the PHY header:
**.recordPcap = true
**.dumpProtocols = "ethernetphy"
**.checksumMode = "computed"
**.fcsMode = "computed"
Here is the configuration of traffic generation in host1:
*.host1.numApps = 2
*.host1.app[*].typename = "UdpSourceApp"
*.host1.app[0].source.packetNameFormat = "background-%c"
*.host1.app[1].source.packetNameFormat = "ts-%c"
*.host1.app[*].tagger.typename = "PacketTagger"
*.host1.app[0].tagger.vlanId = 1
*.host1.app[1].tagger.vlanId = 0
*.host1.app[*].io.destAddress = "host2"
*.host1.app[0].io.destPort = 1000
*.host1.app[1].io.destPort = 1001
There are two UdpApp’s in host1, one is generating background traffic (low priority)
and the other high-priority traffic. The UDP apps put VLAN tags on the packets, and the Ethernet
MAC uses the VLAN ID contained in the tags to classify the traffic into high and low priorities.
We set up a high-bitrate background traffic (96 Mbps) and a lower-bitrate high-priority traffic (9.6 Mbps), both with 1200B packets. Their sum is intentionally higher than the 100 Mbps link capacity (we want non-empty queues); excess packets will be dropped.
# background ~96Mbps
*.host1.app[0].source.packetLength = 1200B
*.host1.app[0].source.productionInterval = truncnormal(100us,50us)
*.host1.app[0].source.initialProductionOffset = 5us
# high-ts ~9.6Mbps
*.host1.app[1].source.packetLength = 1200B
*.host1.app[1].source.productionInterval = truncnormal(1ms,500us)
The FifoQueueing configuration uses no preemption or priority queue. The configuration just limits
the EthernetMacPhy’s queue length to 4.
In all three cases, the queues need to be short to decrease the queueing time’s effect on the measured delay. However, if they are too short, they might be empty too often, which renders the priority queue useless (it cannot prioritize if it contains just one packet, for example). The queue length of 4 is an arbitrary choice. The queue type is set to DropTailQueue so that it can drop packets if the queue is full.
[Config FifoQueueing]
description = "High and low priority frames are transmitted in first-in first-out order"
**.macLayer.queue.packetCapacity = 4
**.macLayer.queue.typename = "DropTailQueue"
In the PriorityQueueing configuration, we change the queue type in the MAC layer from the
default PacketQueue to PriorityQueue:
[Config PriorityQueueing]
description = "High priority frames are transmitted before low priority frames"
**.macLayer.queue.typename = "PriorityQueue"
**.macLayer.queue.numQueues = 2
**.macLayer.queue.queue[*].packetCapacity = 4
**.macLayer.queue.queue*.typename = "DropTailQueue"
**.macLayer.queue.classifier.classifierClass = "inet::PacketVlanReqClassifier"
The priority queue utilizes two internal queues for the two traffic categories. To limit the queueing time’s effect on the measured end-to-end delay, we also limit the length of internal queues to 4. We also set the queue type to DropTailQueue. We use the priority queue’s classifier to put packets into the two traffic categories.
In the FramePreemption configuration, we replace the EthernetMacLayer and
EthernetPhyLayer modules default in LayeredEthernetInterface with
EthernetPreemptingMacLayer and EthernetPreemptingPhyLayer,
which support preemption.
[Config FramePreemption]
description = "Transmission of low priority frames are preempted by high priority frames"
*.host*.eth[0].macLayer.typename = "EthernetPreemptingMacLayer"
*.host*.eth[0].phyLayer.typename = "EthernetPreemptingPhyLayer"
**.macLayer.*.queue.packetCapacity = 4
**.macLayer.*.queue.typename = "DropTailQueue"
There is no priority queue in this configuration. The two MAC submodules both have their own queues. We also limit the queue length to 4 and configure the queue type to be DropTailQueue.
Note
We could also have just one shared priority queue in the EthernetPreemptingMacLayer module, but this is not covered here.
We use the following traffic for the RealisticFifoQueueing, RealisticPriorityQueueing,
and RealisticFramePreemption configurations:
# background traffic ~96Mbps
*.host1.app[0].source.packetLength = 1200B
*.host1.app[0].source.productionInterval = truncnormal(100us,50us)
# time-sensitive traffic ~9.6kbps
*.host1.app[1].source.packetLength = 120B
*.host1.app[1].source.productionInterval = truncnormal(10ms,5ms)
In this traffic configuration, high-priority packets are 100 times less frequent and are 1/10th the size of low-priority packets.
Transmission on the Wire¶
In order to make sense of how frame preemptions are represented in the OMNeT++ GUI (in Qtenv’s animation and packet log and in the Sequence Chart in the IDE), it is necessary to understand how packet transmissions are modeled in OMNeT++.
Traditionally, transmitting a frame on a link is represented in OMNeT++ by sending a “packet”.
The “packet” is a C++ object (i.e., a data structure) which is of or is subclassed from
the OMNeT++ class cPacket. The sending time corresponds to the start of the transmission.
The packet data structure contains the length of the frame in bytes and also the (more
or less abstracted) frame content. The end of the transmission is implicit: it is
computed as start time + duration, where duration is either explicit or derived
from the frame size and the link bitrate. This approach in vanilla form is, of course,
not suitable for Ethernet frame preemption because it is not known in advance whether
or not a frame transmission will be preempted and at which point.
Instead, in OMNeT++ 6.0, the above approach was modified to accommodate new use cases. In the new approach, the original packet sending remains, but its interpretation changes slightly. It now represents a prediction: “this is a frame whose transmission will go through unless we say otherwise”. Namely, while the transmission is ongoing, it is possible to send transmission updates, which modify the prediction about the remaining part of the transmission. A transmission update packet essentially says “ignore what I said previously about the total frame size/content and transmission time, here’s how much time the remaining transmission is going to take according to the current state of affairs, and here’s the updated frame length/content”.
A transmission update may truncate, shorten, or extend a transmission (and the frame). For technical reasons, the transmission update packet carries the full frame size and content (not just the remaining part), but it must be crafted by the sender in a way that it is consistent with what has already been transmitted (it cannot alter the past). For example, truncation is done by indicating zero remaining time and setting the frame content to what has been transmitted up to that point. An updated transmission may be further modified by subsequent transmission updates. The end of the transmission is still implicit (it finishes according to the last transmission update), but it is also possible to make the ending explicit by sending a zero-remaining-time transmission update at exactly the time the transmission would otherwise end. After the transmission’s end time has passed, it is naturally not possible to send any more transmission updates for it (we cannot modify the past).
In light of the above, it is easy to see why a preempted Ethernet frame appears in e.g. Qtenv’s packet log multiple times: the original transmission and the subsequent transmission update(s) are all packets.
The first one is the original packet, which contains the full frame size/content and carries the prediction that the frame transmission will go through uninterrupted.
The second one is sent at the time the decision is made inside the node that the frame is going to be preempted. At that time, the node computes the truncated frame and the remaining transmission time, taking into account that at least the current octet and FCS need to be transmitted, and there is a minimum frame size requirement as well. The packet represents the size/content of the truncated frame, including FCS.
In the current implementation, the Ethernet model also sends an explicit end-transmission update with zero remaining transmission duration and identical frame size/content as the previous one. This would not be strictly necessary and may change in future INET releases.
The above packets are distinguished using name suffixes: :progress and :end are
appended to the original packet name for transmission updates and for the explicit end-transmission,
respectively. In addition, the packet itself is also renamed by adding -frag0, -frag1,
etc. to its name, to make frame fragments distinguishable from each other. For example,
a frame called background3 may be followed by background3-frag0:progress and
background3-frag0:end. After the intervening express frame has also completed transmission,
background3-frag1 will follow (see video in the next section).
Results¶
Frame Preemption Behavior¶
Here is a video of the frame preemption behavior:
The Ethernet MAC in host1 starts transmitting background-3. During the transmission,
a high-priority frame (ts-1) arrives at the MAC. The MAC interrupts the transmission of
background-3; in the animation, background-3 is first displayed as a whole frame,
then changes to background-3-frag0:progress when the high-priority frame is available.
After transmitting the high-priority frame, the remaining fragment of background-3-frag1
is transmitted.
The frame sequence is displayed in the Qtenv packet log:

As mentioned in the previous section, a preempted frame appears multiple times
in the packet log, as updates to the frame are logged. At first, background-3
is logged as an uninterrupted frame. When the high-priority frame becomes available,
the frame name changes to background-3-frag0, and it is logged separately.
Actually, only one frame named background-3-frag0 was sent before ts-1,
but with three separate packet updates.
The same frame sequence is displayed on a sequence chart on the following images, with a different frame selected and highlighted in red on each image. Note that the timeline is non-linear:
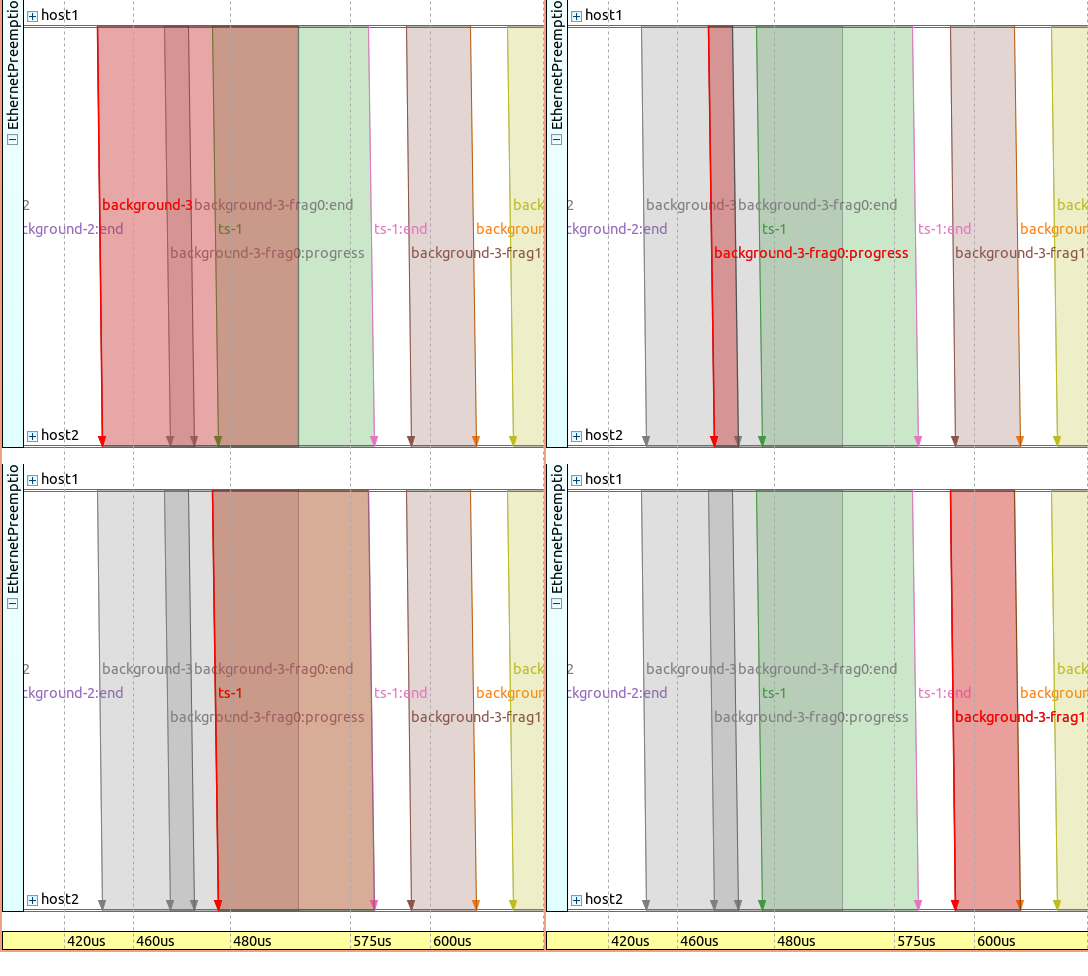
Just as in the packet log, the sequence chart contains the originally intended,
uninterrupted background-3 frame as it is logged when its transmission is started.
Note
You can think of it as there are actually two time dimensions present on the sequence chart: the events and messages as they happen at the moment, and what the modules “think” about the future, i.e., how long will a transmission take. In reality, the transmission might be interrupted, and so both the original (background-3) and the “updated” (background-3-frag0) is present on the chart.
Here is the frame sequence on a linear timeline, with the background-3-frag0 frame highlighted:
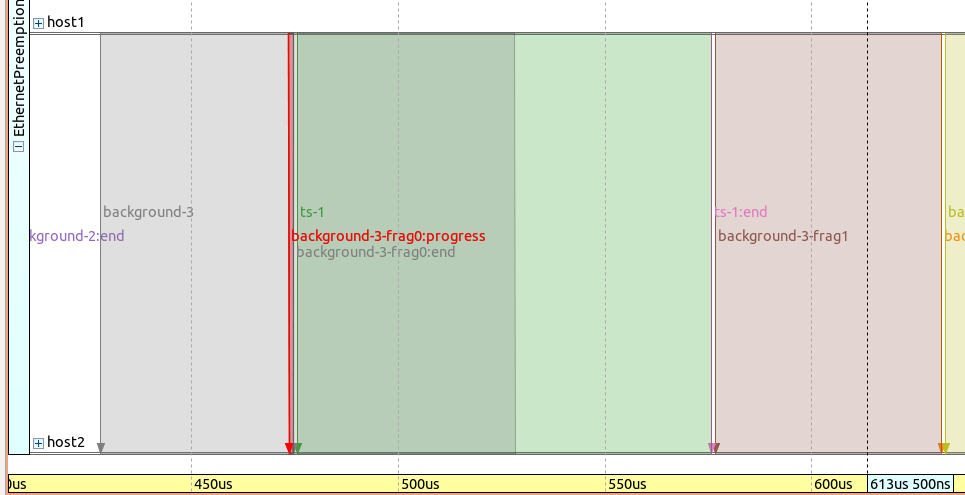
Note that background-3-frag0:progess is very short (it basically contains
just an updated packet with an FCS, as a remaining data part of the first fragment).
Transmission of ts-1 starts after a short interframe gap.
Here is the same frame sequence displayed in Wireshark:
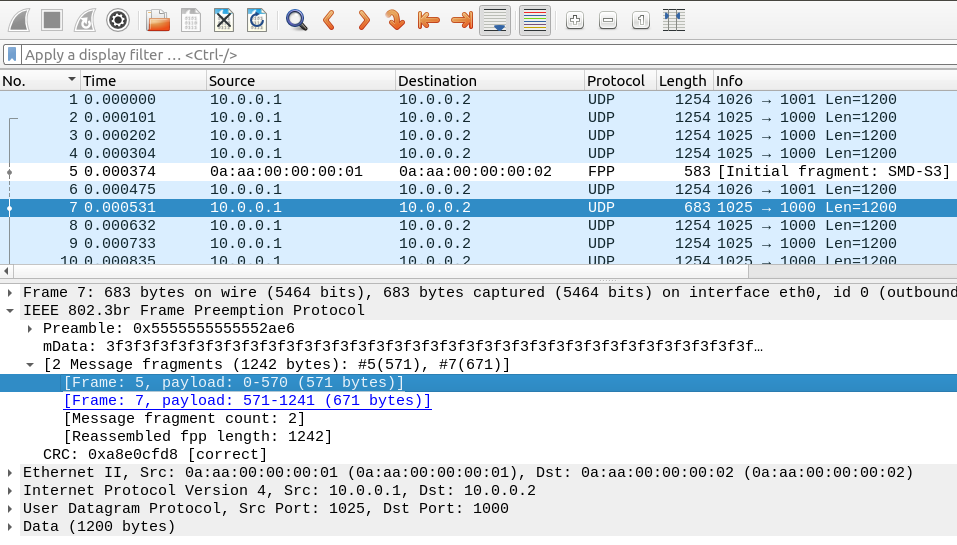
The frames are recorded in the PCAP file at the end of the transmission of
each frame or fragment, so the originally intended 1243B background-3
frame frame is not present there, only the two fragments.
In the Wireshark log, frame 5 and frame 7 are the two fragments of
background-3. Note that FPP refers to Frame Preemption Protocol;
frame 6 is ts-1, sent between the two fragments.
Here is background-3-frag1 displayed in Qtenv’s packet inspector:
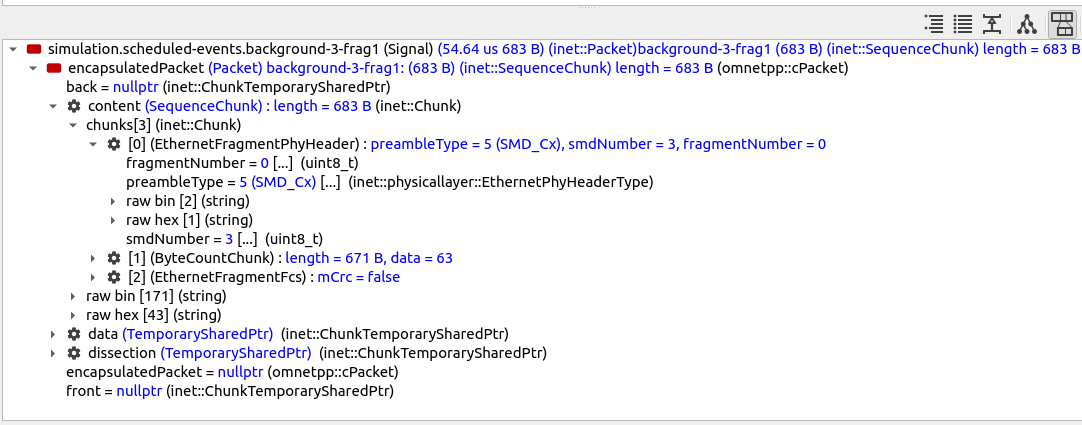
This fragment does not contain a MAC header because it is the second part of the original Ethernet frame.
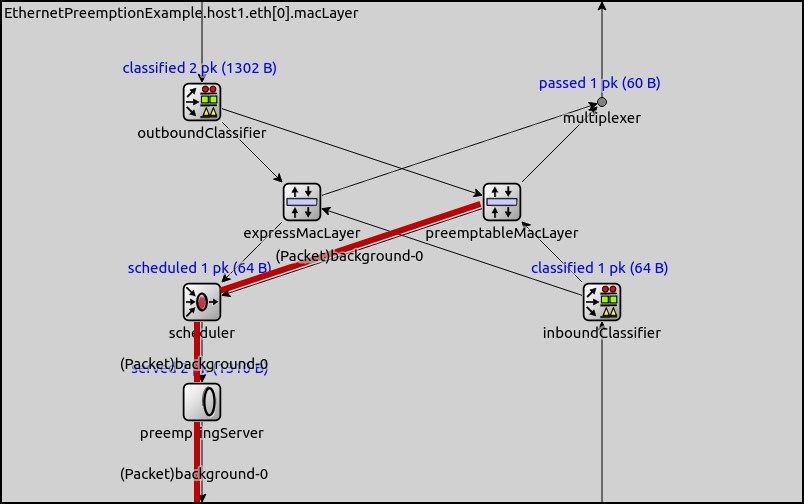
The paths which the high and low priority (express and preemptable) packets take in the EthernetPreemptingMacLayer are illustrated below by the red lines:
Analyzing End-to-End Delay¶
Simulation Results¶
To analyze the results for the identical packet length configurations, we plot the end-to-end delay averaged on [0,t] of the UDP packets for the three cases on the following chart. Note that the configuration is distinguished using different line styles and the traffic category by colors:
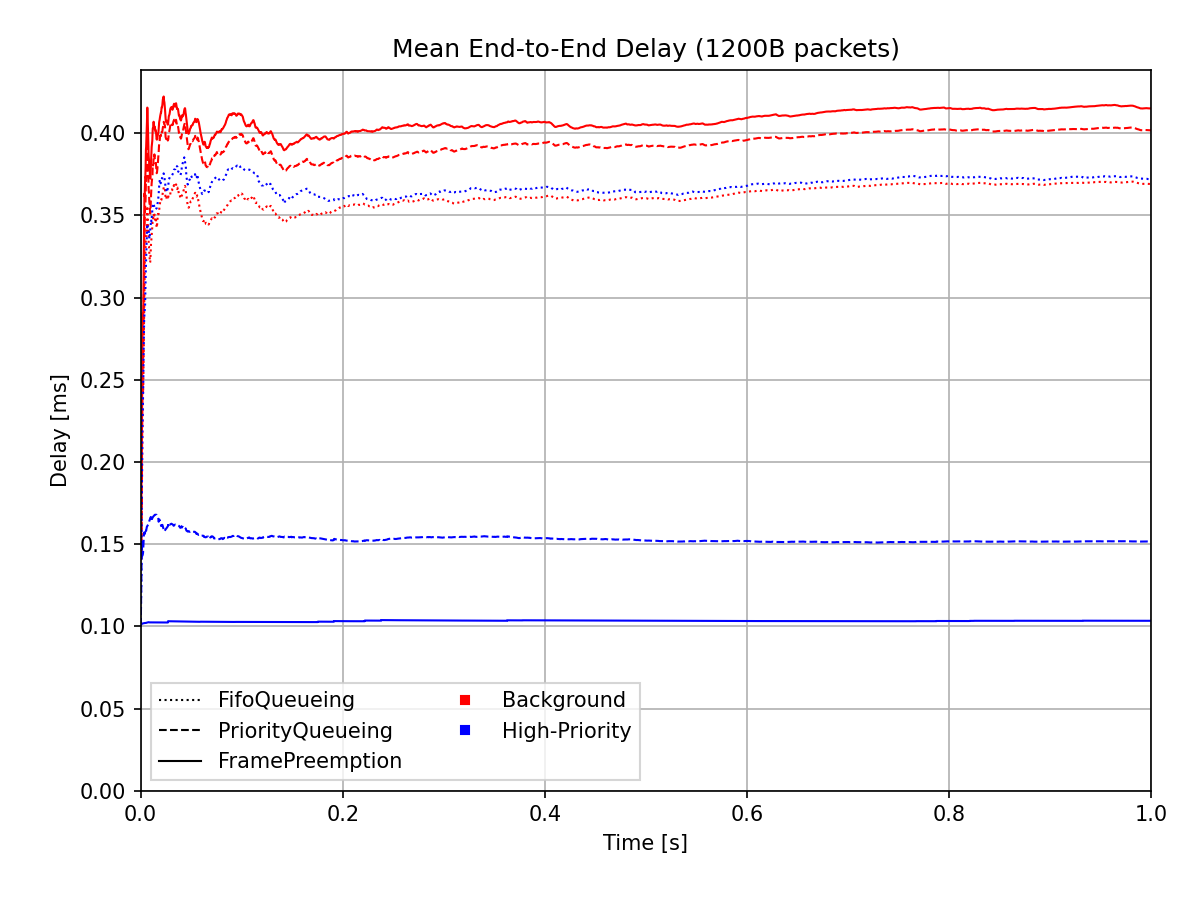
The chart shows that in the case of the default configuration, the delay for the two traffic categories is about the same. The use of the priority queue significantly decreases the delay for the high-priority frames and marginally increases the delay of the background frames compared to the baseline default configuration. Preemption causes an even greater decrease for high-priority frames at the cost of a slight increase for background frames.
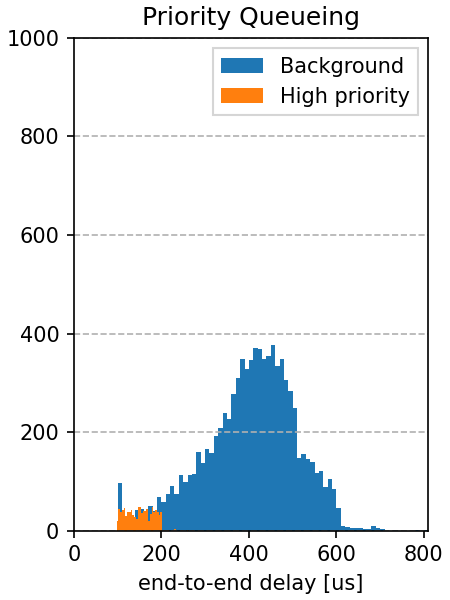
This is visible on the end-to-end delay histograms for the three cases:
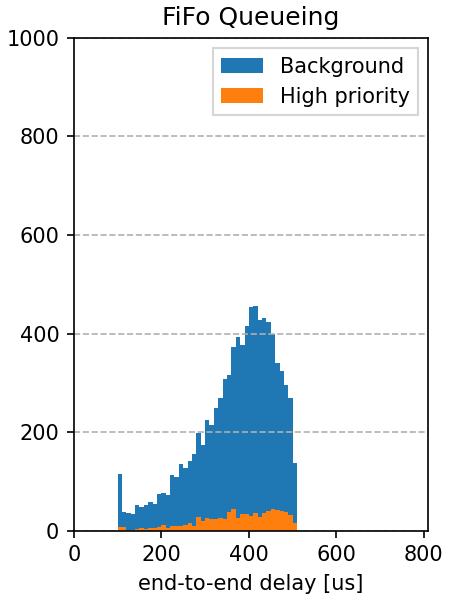
|
|
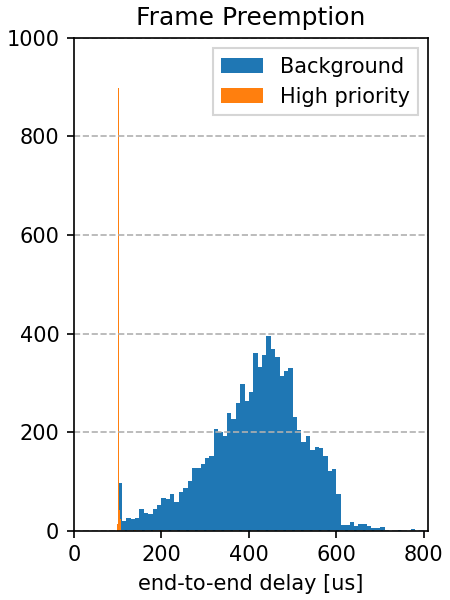
|
Estimating the End-to-End Delay¶
In the next section, we will examine the credibility of these results by doing some back-of-the-envelope calculations.
FifoQueueing Configuration¶
For the FifoQueueing configuration, the MAC stores both background and high-priority
packets in the same FIFO queue. Thus, the delay of the two traffic categories is
about the same. Due to high traffic, the queue always contains packets. The queue
is limited to 4 packets, so the queueing time has an upper bound: about the
transmission time of 4 frames. Looking at the queue length statistics (see anf file),
we can see that the average queue length is ~2.6, so packets suffer an average queueing
delay of 2.6 frame transmission durations.
The end-to-end delay is roughly the transmission duration of a frame + queueing delay + interframe gap. The transmission duration for a 1200B frame on 100Mbps Ethernet is about 0.1ms. On average, there are two frames in the queue so frames wait two frame transmission durations in the queue. The interframe gap for 100Mbps Ethernet is 0.96us, so we assume it negligible:
delay ~= txDuration + 2.6 * txDuration + IFG = 3.6 * txDuration = 0.36ms
PriorityQueueing Configuration¶
For the PriorityQueueing configuration, high-priority frames have their own sub-queue in
the PriorityQueue module in the MAC. When a high-priority frame arrives at the queue, the
MAC will finish the ongoing low-priority transmission (if there is any) before beginning
the transmission of the high-priority frame. Thus high-priority frames can be delayed,
as the transmission of the current frame needs to be finished first. Still, using a priority
queue decreases the delay of the high-priority frames and increases that of the background
frames compared to just using one queue for all frames.
Due to high background traffic, a frame is always present in the background queue. A high-priority frame needs to wait until the current background frame transmission finishes; on average, the remaining duration is half the transmission duration of a background frame:
delay ~= txDuration + 0.5 * txDuration + IFG = 1.5 * txDuration = 0.15ms
FramePreemption Configuration¶
For the FramePreemption configuration, the high-priority frames have their own queue in the MAC.
When a high-priority frame becomes available, the current background frame transmission
is almost immediately stopped.
The delay is roughly the duration of an FCS + transmission duration + interframe gap. The duration of an FCS is about 1us, so we neglect it in the calculation (as previously, the interframe gap is neglected as well):
delay = txDuration + fcsDuration + IFG ~= txDuration = 0.1ms
The calculated values above roughly match the results of the simulation.
Realistic Traffic¶
The mean end-to-end delay for the realistic traffic case is plotted on the following chart:
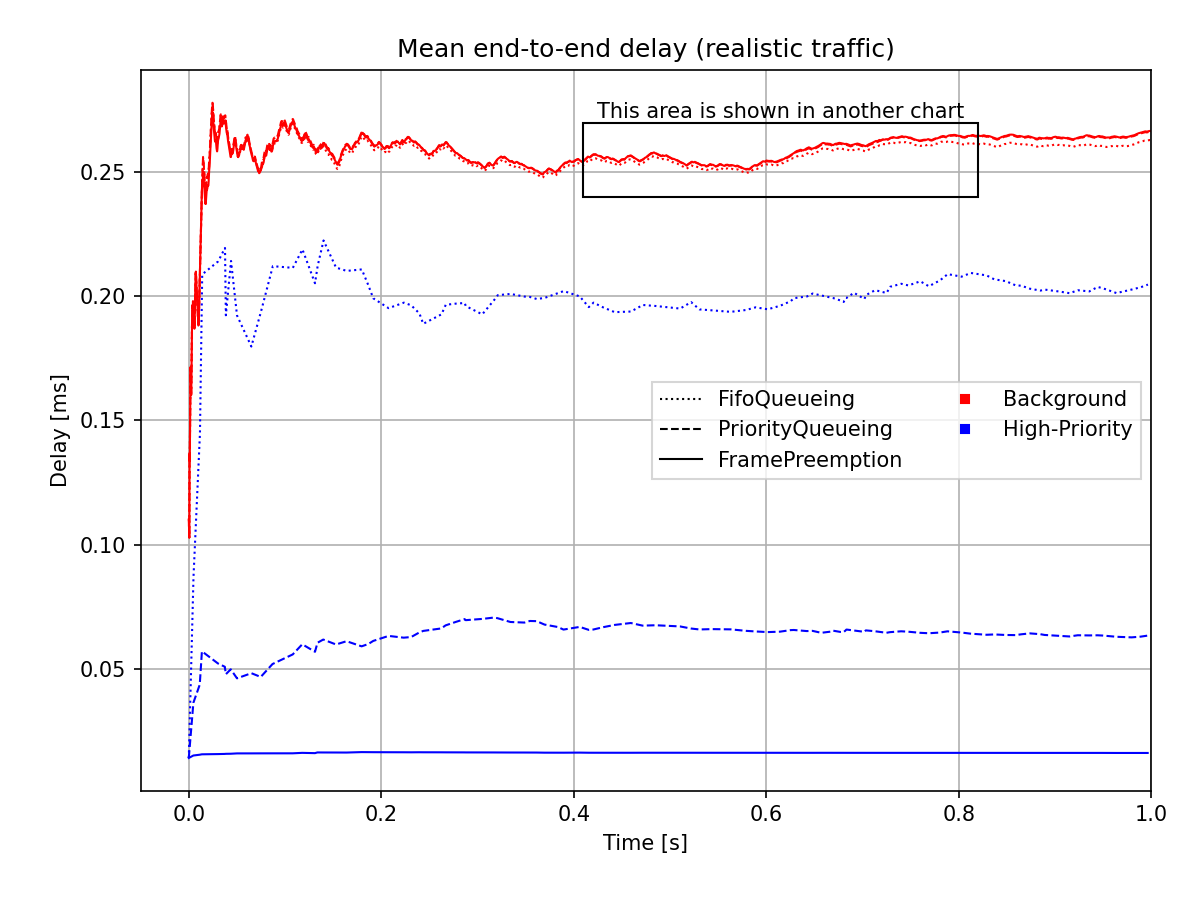
The range indicated by the rectangle on the chart above is shown zoomed in on the chart below, so that it’s more visible:
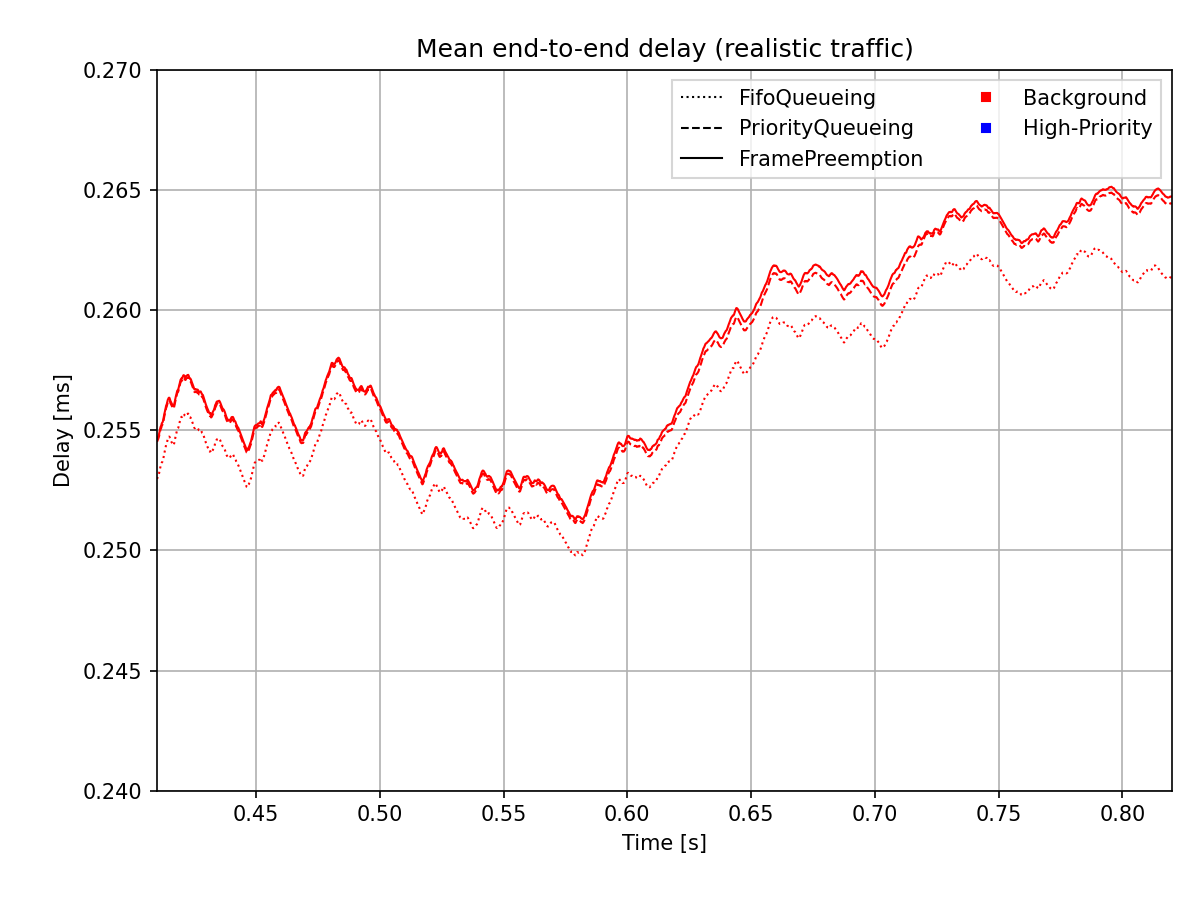
As described above, the end-to-end delay of high-priority frames when using preemption is independent of the length of background frames. The delay is approximately the transmission duration of a high-priority frame (apparent in the case of both the realistic and the comparable length traffic results).
In the case of realistic traffic, the delay of the background frames is not affected by either the use of a priority queue or preemption. The delay of the high-priority frames is reduced significantly because the traffic is different (originally, both the background and high-priority packets had the same length, so they could be compared for better demonstration).
Sources: omnetpp.ini, FramePreemptionShowcase.ned
Try It Yourself¶
If you already have INET and OMNeT++ installed, start the IDE by typing
omnetpp, import the INET project into the IDE, then navigate to the
inet/showcases/tsn/framepreemption folder in the Project Explorer. There, you can view
and edit the showcase files, run simulations, and analyze results.
Otherwise, there is an easy way to install INET and OMNeT++ using opp_env, and run the simulation interactively.
Ensure that opp_env is installed on your system, then execute:
$ opp_env run inet-4.6 --init -w inet-workspace --install --build-modes=release --chdir \
-c 'cd inet-4.6.*/showcases/tsn/framepreemption && inet'
This command creates an inet-workspace directory, installs the appropriate
versions of INET and OMNeT++ within it, and launches the inet command in the
showcase directory for interactive simulation.
Alternatively, for a more hands-on experience, you can first set up the workspace and then open an interactive shell:
$ opp_env install --init -w inet-workspace --build-modes=release inet-4.6
$ cd inet-workspace
$ opp_env shell
Inside the shell, start the IDE by typing omnetpp, import the INET project,
then start exploring.
Discussion¶
Use this page in the GitHub issue tracker for commenting on this showcase.